$ aggregate League of Legends champion mastery across all your accounts
League of Legends players who play on multiple accounts have no built-in way to see their total champion mastery across all accounts at once.
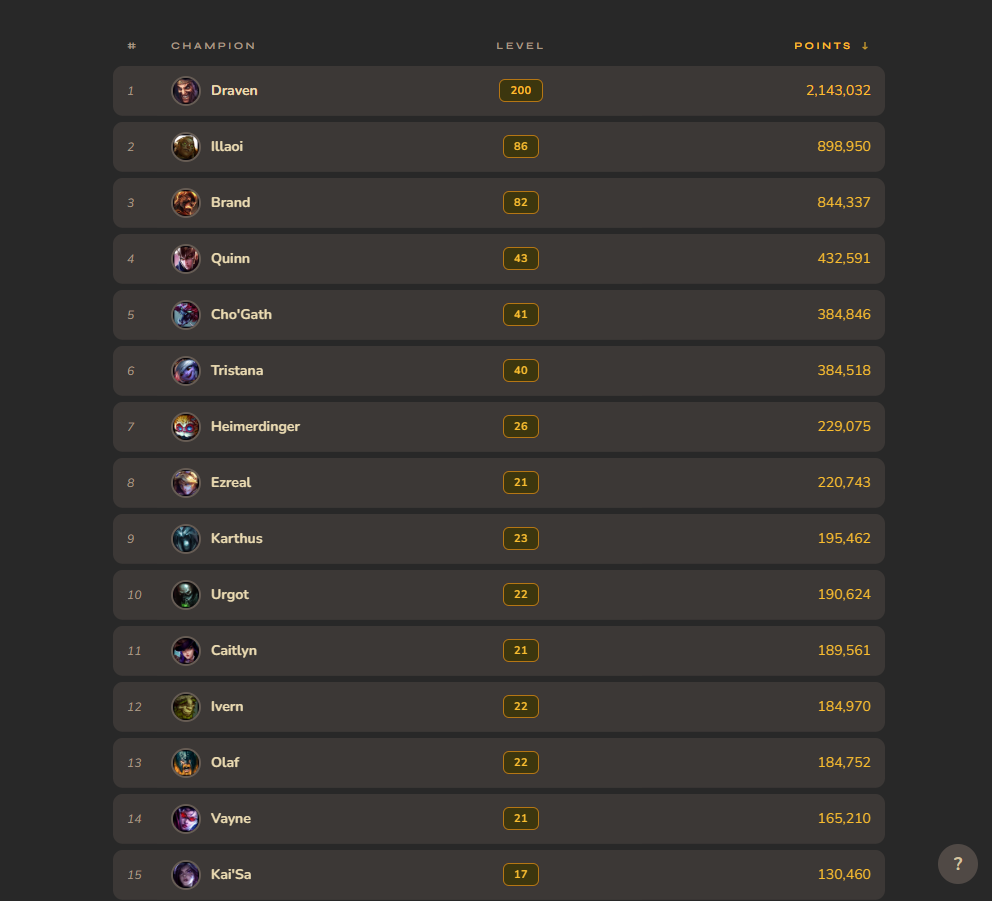
LOLSUMMD aggregates mastery data from up to 10 accounts (any region) into a single mastery table. Try it with this example link to see it pre-loaded with accounts.
Note: currently running on a development API key. Some requests may occasionally fail pending production approval from Riot.
SummonerName#TAG directly. The app splits it for you automatically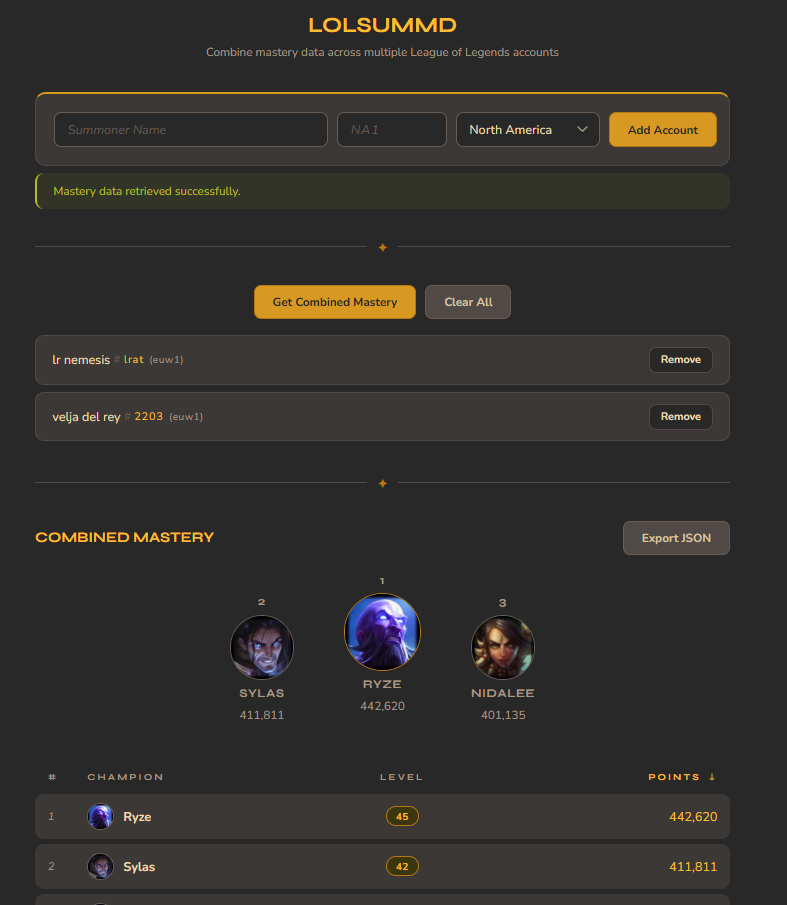
 hunter baker
hunter baker